要点
- AI文字起こしは音声を素早くテキスト化できますが、精度は録音品質、話者の重なり、音声内の語彙(専門用語・固有名詞など)に大きく左右されます。
- 最もシンプルで信頼できる流れは、音声を準備 → 文字起こし → 冒頭を早めに確認 → 重要度の高い誤り(氏名・数字)を修正 → 必要な形式で書き出し、です。
- 「無料」のAI文字起こしは、分数上限、エクスポート制限、保存期間の短さが付くことが多いので、本格的に使う前に短いクリップでテストしましょう。
- 言語設定の間違い、話者ラベルの省略、プライバシー設定を確認せずに機密性のある文字起こしを共有する—といったよくあるミスは避けましょう。
「AI transcription(AI文字起こし)」とは何か(そして何ではないか)
AI文字起こしとは、自動音声認識(ASR)モデルを使って、音声(または動画の音声トラック)を文字テキストに変換するソフトウェアのことです。
得意なこと:
- 数分で使える下書きを作る
- 音声を検索可能にする(引用や意思決定の箇所を探すのに便利)
- 動画向けの字幕ファイル(SRT/VTTなど)を作る
不得意/誤解されがちなこと:
- 特に雑音が多い・複数人が話す会議で「100%正確」を保証すること
- 「AI会議メモ」や要約と同じもの(多くの場合、要約は文字起こしの後に行う別ステップです)
音声→テキスト vs. 「AIメモ」 vs. 会議の要約
- 音声文字起こし(文字起こし):「何が話されたか」を一行ずつ記録します。
- AIメモ:要点を整理した読みやすい形(ハイライト付きの場合もあります)。
- 要約/アクションアイテム:役に立つ一方、元の文字起こしが弱いとニュアンスを落とすことがあります。
コンプライアンス、引用、字幕、詳細なレビューが目的なら、まずは品質の高い文字起こしを作るところから始めましょう。
なぜ精度に大きな差が出るのか
AI文字起こしの精度は、いくつかの要因で大きく変動します:
- 音声品質:背景ノイズ、反響、音量が小さい、音割れ
- 話者の状況:かぶり(同時発話)、テンポの速いやり取り、割り込み
- アクセントと明瞭さ:地域差のある発音、聞き取りにくい話し方、マイクからの距離
- 語彙:製品名、略語、業界用語、固有名詞
- 言語設定:言語/方言の選択ミスは、音が良くても結果を大きく崩します
AI文字起こしが向いている場面(そして人の手が必要な場面)
AI文字起こしは、スピード重視で、軽い編集で使える下書きが欲しいときに向いています(会議、インタビュー、授業、ポッドキャスト、顧客通話など)。
一方で、次のような場合は人手(または重めの編集)が必要になることがあります:
- 法的に重要で機密性の高い音声
- 話者数が多く、かぶりが多い
- 公開用に、氏名/肩書き/引用を完璧に整える必要がある

文字起こし前:精度を上げるための簡単チェックリスト
準備に2〜5分かけるだけで、結果はかなり良くなります。
入力素材を選ぶ
音声 vs. 動画:文字起こし品質で重要なのは?
動画だからといって自動的に精度が上がるわけではありません。重要なのは音声トラックです:
- 話者がマイクに近いか?
- 部屋の反響が多いか?
- 音声が強く圧縮されていないか?(画面録画でよくあります)
選べるなら、マイク近くで録ったクリアな音声(スマホを近くに置いた録音でも)ほうが、音が悪い「きれいな動画」より結果が良いことがあります。
対応ファイル形式と長さ制限を確認
多くのツールはMP3/WAV/M4A/MP4/MOVなど一般的な形式に対応しますが、「無料」プランでは次のような制限が付きがちです:
- 最大ファイルサイズ
- 1回のアップロードあたりの最大分数
- エクスポート回数
録音が長い場合は、論理的な区切りで分割するのがおすすめです(例:30〜60分ごと)。
録音を改善する(録り直せなくてもできる範囲で)
ノイズと反響を減らす(簡単な対策)
再収録できるならそれがベストです。難しい場合でも、ちょっとした処理が効きます:
- 編集ソフトのノイズリダクションを使う(強すぎると音声が歪むので軽めに)
- 長い無音区間をトリミングする
- 音が小さすぎる場合は音量を正規化する
マイクに近づき、レベルを安定させる(次回のために)
次回以降の録音では:
- 思っているよりマイクを近づける
- 大きな部屋の端から録らない
- オンライン会議ではヘッドホンを使い、反響やハウリングを減らす
話者と文脈を整理する
話者ラベル用に名前/肩書きを用意する
ツールが話者ラベル(多くは話者分離/ダイアライゼーションと表記)に対応している場合、先に名前を把握しておくと後工程が速くなります。例えば:
- Speaker 1 = Alex(営業)
- Speaker 2 = Priya(顧客)
…のようなメモがあるだけで編集がかなり楽になります。
略語や専門用語の「用語リスト」を作る
次のようなものを書き出しておきましょう:
- 製品名
- 略語
- 技術用語
- 人名
検索/置換で繰り返しの誤りをまとめて直すときに役立ちます。
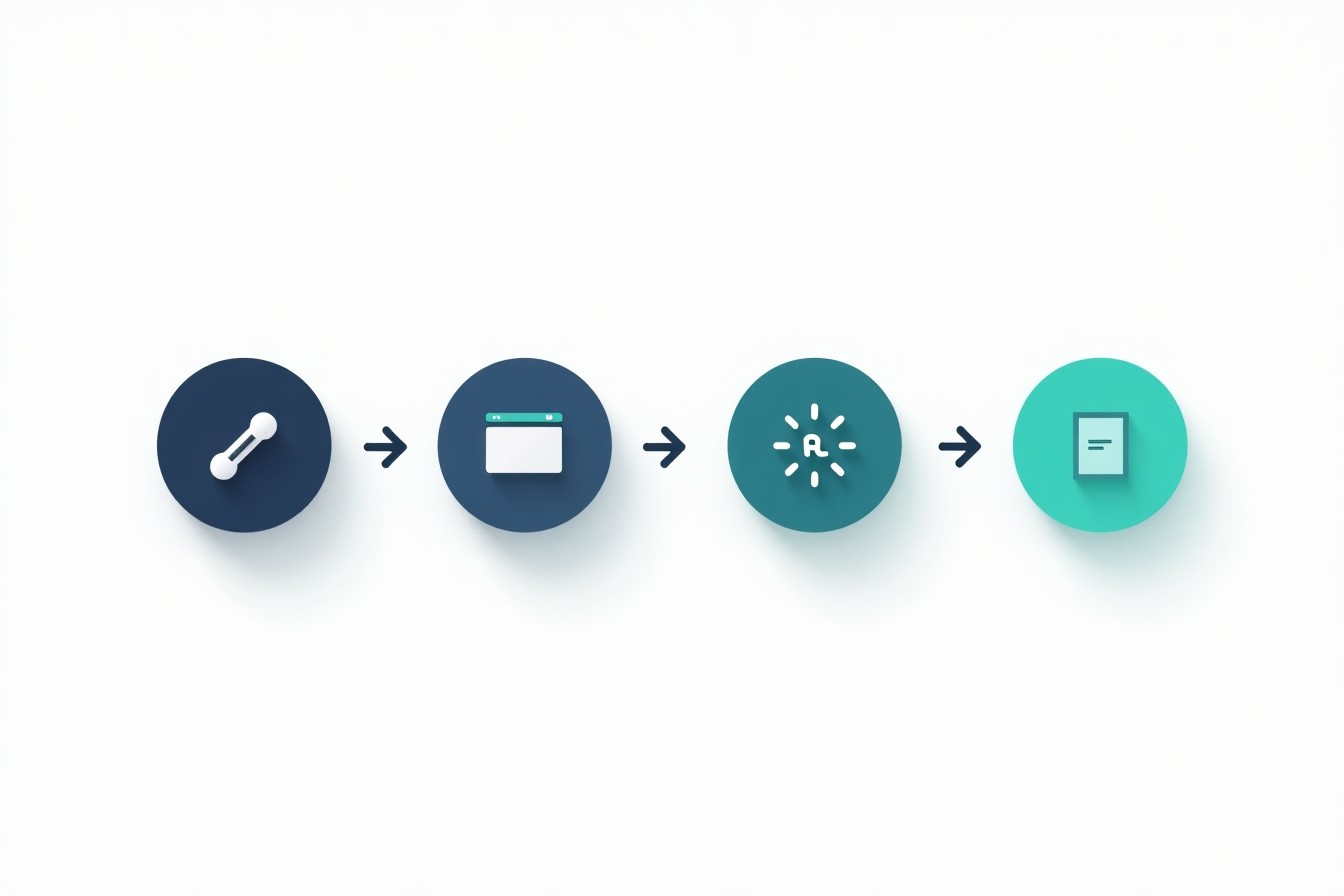
AIで文字起こしする方法:実務向けステップ別ワークフロー
会議、インタビュー、講義、動画など、ほとんどのケースで使える手順です。
ステップ1:ファイルをアップロードする/直接録音する
多くのツールには次のどちらか(または両方)の方法があります:
- アップロード:既存の録音に最適
- ライブ録音:会議や簡単なメモに便利
動画を文字起こしする場合は、動画ファイルをアップロードし、ツール側で音声を抽出するのが一般的です。
リンク(Zoom/Meet/Teams)や画面録画しかない場合
ツールがリンクから文字起こしできない場合は:
- まず録画をダウンロードする(または音声を書き出す)
- 必要なら一般的な形式に変換する(音声はMP3、動画はMP4が無難)
アップロード録音を頻繁に扱うなら、音声→テキスト変換ツールを使うと、アップロード→文字起こしの流れがシンプルになります。
ステップ2:言語と設定を選ぶ(可能なら)
言語を選ぶ画面が出たら省略しないでください。設定ミスは、出力が悪くなる最も典型的な原因です。
探したい設定例:
- 言語/方言(例:英語 US と他の変種)
- 句読点(自動句読点は読みやすさに効きます)
- タイムスタンプ(レビューや字幕に便利)
- 話者分離(ダイアライゼーション)(話者を分ける)
言語選択、句読点、タイムスタンプ、話者分離について
- 後で特定の箇所を参照する必要があるなら(インタビュー、講義、法務レビューなど)、タイムスタンプを有効にしましょう。
- 複数話者なら話者分離を使いましょう。ないと「誰が何を言ったか」を推理しながら編集する羽目になります。
ステップ3:走らせたら、最初の1分をざっと確認する
おすすめの習慣は、生成が始まったら最初の1分を確認することです。
最初の1分が明らかにおかしい(言語が違う、単語が崩れている、文が抜けている)場合は、最後まで待たずに設定や音声を先に直しましょう。
ステップ4:重要度の高い誤りから先に直す
優先すべきポイント:
- 氏名、数字、日付
- 技術用語、略語
- 話者ラベル(必要に応じて)
ステップ5:本当に必要な形式でエクスポートする
よくある出力形式:
- プレーンテキスト/DOCX(編集用)
- SRT/VTT(字幕用)
- PDF(共有用)
動画コンテンツの文字起こしが中心なら、「音声だけ」として扱うより、動画→テキスト変換フローのほうが適したケースが多いです。

よくある質問
無料のAI文字起こしはありますか?
はい。多くのツールに無料プランがありますが、分数の上限、エクスポート制限、保存期間の短縮などが付くことが多いです。まずは短いクリップで試してから判断しましょう。
文字起こしに最適なAIはどれですか?
用途次第です(単一話者か複数話者か、タイムスタンプ、字幕出力、プライバシー要件など)。現実的には、同じ2〜3分のサンプルを複数ツールで試し、結果を比較するのが確実です。
文字起こし精度を上げるにはどうすればいいですか?
録音品質を改善し、正しい言語を選び、複数話者なら話者分離を有効にし、氏名/数字を早めに修正しましょう。
次のステップ
録音をきれいな文字起こしに変換し(さらに要約やアクションアイテムにも再利用したい)なら、まずはこちら:Proactor。